
一直以来发现对Python的包管理中涉及的机制不是特别清晰,于是打算整理一下做个分析
一、模块是什么
我们在进行单文件Python编程时,会按照层级化的设计思想将功能实现的流程拆分为函数和类来实现。而对于规模更加庞大的项目,同样要保持层级化单元化的设计思路,于是Python就设计了模块(module)这一结构。

在官方文档中,关于module的描述是这样的
A module is a file containing Python definitions and statements. The file name is the module name with the suffix .py appended. Within a module, the module’s name (as a string) is available as the value of the global variable <__name__>.
不那么严谨地说,模块(module)就是一个Python文件,它包含了Python定义和语句。它是Python将完整大型程序拆分单元进行管理中的产物。从某种程度上来说,其他编程语言中的多文件编程在Python中被抽象成了多模块编编程
我们在Python文件中使用import引用时,就是在引入模块
初看模块这一概念,如果真的只像简单描述说明的这样,似乎就变成了.py文件这一概念的外号了,显得作用不大
但其实继续探究之后,模块的这一组织方式其实有更加细致的设计
在Python解释器解释我们的Python文件时,在解释import xxmodule 这样的语句时,本质上并不是简单的导入文件内容,而是从模块文件中加载了一个module object
为了研究这一点,我们可以创建一个实验文件夹,并在文件夹中创建两个文件——main.py和mymodule.py两个文件
mymodule.py暂时保持为空,在main.py中我们编写以下代码
import mymodule
print(mymodule)执行main.py,我们可以发现,Python将引入之后的mymodule解释为一个module变量,同时还包含了这个module 的来源信息(我们的mymodule.py文件)

同时值得注意的是,在执行完main.py文件,完成了对mymodule这个模块的引入之后,我们的文件夹中多了一个新的文件夹,此时我们的文件结构变成了这样
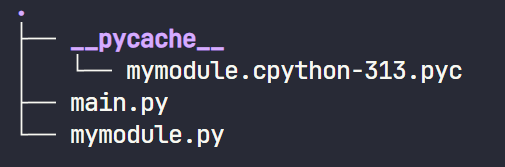
这是因为Python为了加速module的加载过程,会把module的编译版本文件(*.pyc)保存在指定名字的文件夹__pycache__ 中